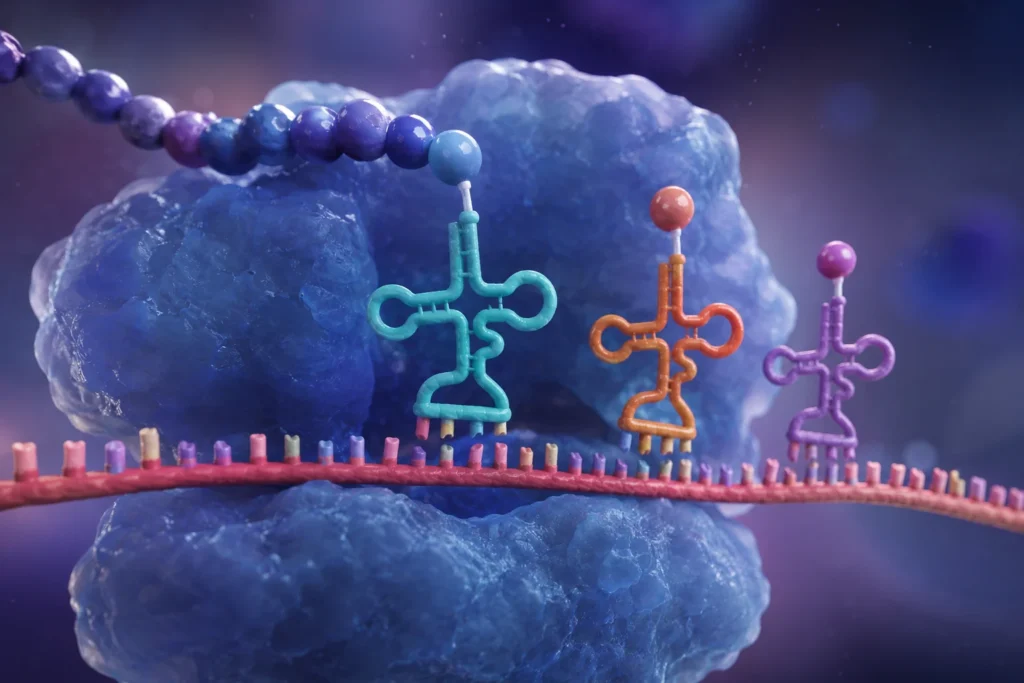
El ARN de transferencia (ARNt) constituye uno de los componentes más importantes y especializados del sistema de traducción genética. Su función esencial consiste en actuar como molécula adaptadora entre el lenguaje de los ácidos nucleicos y el lenguaje de las proteínas. Mientras que la información genética se almacena y transmite mediante secuencias de nucleótidos en el ADN y el ARN mensajero (ARNm), las proteínas están formadas por secuencias de aminoácidos. Debido a que no existe una afinidad química directa capaz de traducir espontáneamente una secuencia de nucleótidos en una secuencia de aminoácidos, la célula requiere moléculas intermediarias que establezcan dicha correspondencia. El ARNt desempeña precisamente esta función, permitiendo que la información codificada en los codones del ARNm sea convertida con extraordinaria precisión en la secuencia aminoacídica de una proteína.
Cada molécula de ARNt es específica para un aminoácido determinado y posee la capacidad de reconocer uno o varios codones particulares presentes en el ARNm. Esta doble especificidad convierte al ARNt en el principal enlace funcional entre la información genética y la síntesis proteica. Sin la participación de estas moléculas adaptadoras, la traducción del código genético sería imposible, ya que los ribosomas no poseen la capacidad intrínseca de identificar qué aminoácido corresponde a cada codón. Esta función adaptadora fue propuesta teóricamente antes de que se conociera la estructura molecular del ARNt y posteriormente fue confirmada mediante estudios bioquímicos y estructurales que demostraron la existencia de moléculas especializadas capaces de transportar aminoácidos y reconocer secuencias específicas de ARNm.
Las moléculas de ARNt son relativamente pequeñas en comparación con otros tipos de ARN celulares. Generalmente contienen entre 70 y 95 nucleótidos, dependiendo de la especie biológica considerada. A pesar de su reducido tamaño, presentan una organización estructural extraordinariamente compleja y altamente conservada a lo largo de la evolución. La conservación de sus características estructurales en bacterias, arqueas y eucariotas refleja la importancia fundamental de estas moléculas para la supervivencia celular.
La estructura secundaria clásica del ARNt adopta una conformación denominada estructura en trébol. Esta organización surge como consecuencia del apareamiento intramolecular de regiones complementarias de la cadena de ARN. La molécula se pliega formando varios brazos o tallos estabilizados por enlaces de hidrógeno entre bases complementarias. Entre estos elementos destacan el brazo aceptor, el brazo D, el brazo anticodón, el brazo TΨC y un bucle variable cuya longitud puede diferir entre distintos tipos de ARNt.
El brazo aceptor constituye el sitio donde se une covalentemente el aminoácido correspondiente. Todos los ARNt funcionales poseen una secuencia terminal conservada formada por los nucleótidos CCA en su extremo 3’. La adenina terminal de esta secuencia desempeña un papel crítico, ya que su grupo hidroxilo sirve como punto de unión para el aminoácido transportado. La incorporación del aminoácido a este sitio no ocurre espontáneamente, sino que es catalizada por enzimas altamente especializadas denominadas aminoacil-ARNt sintetasas.
Las aminoacil-ARNt sintetasas representan uno de los sistemas de reconocimiento molecular más precisos de toda la biología celular. Existe al menos una aminoacil-ARNt sintetasa específica para cada aminoácido. Estas enzimas reconocen simultáneamente características estructurales particulares tanto del aminoácido como del ARNt correspondiente, asegurando que cada molécula de ARNt sea cargada únicamente con el aminoácido correcto. La precisión de este proceso es extraordinariamente elevada, con tasas de error que pueden ser inferiores a una incorporación incorrecta por cada diez mil o cien mil eventos de aminoacilación. Muchas de estas enzimas poseen además mecanismos de edición molecular que detectan y corrigen errores antes de que el aminoácido incorrecto sea utilizado durante la síntesis proteica.
Aunque la estructura en trébol resulta útil para comprender la organización general del ARNt, la conformación tridimensional real es considerablemente más compleja. Estudios obtenidos mediante cristalografía de rayos X y microscopía electrónica de alta resolución han demostrado que la molécula adopta una forma tridimensional semejante a una letra L. En esta configuración espacial, el extremo aceptor que transporta el aminoácido y el brazo anticodón quedan ubicados en extremos opuestos de la molécula. Esta disposición geométrica permite que el anticodón interactúe con el ARNm mientras el aminoácido transportado se posiciona adecuadamente dentro del centro catalítico del ribosoma para participar en la formación de enlaces peptídicos.
El elemento funcional más característico del ARNt es el anticodón. Este consiste en una secuencia de tres nucleótidos localizada dentro del bucle anticodón. La función del anticodón es reconocer de manera específica un codón complementario presente en el ARNm. Dado que los codones están formados por tripletes de nucleótidos, el anticodón también posee tres nucleótidos organizados de manera que puedan establecer apareamientos complementarios mediante enlaces de hidrógeno.
Durante la traducción, el anticodón y el codón interactúan mediante las reglas clásicas de complementariedad de bases. La adenina se aparea con uracilo, mientras que la citosina se aparea con guanina. Esta complementariedad asegura que únicamente determinados ARNt puedan reconocer codones específicos. Por ejemplo, un codón determinado del ARNm podrá ser reconocido únicamente por moléculas de ARNt cuyos anticodones posean la secuencia complementaria adecuada.
La orientación de esta interacción es antiparalela. Mientras el codón del ARNm se lee en dirección 5’→3’, el anticodón se orienta en dirección 3’→5’. Esta disposición antiparalela constituye una característica universal de los procesos de apareamiento entre ácidos nucleicos y resulta esencial para la formación correcta de los enlaces de hidrógeno que estabilizan el complejo codón-anticodón.
La especificidad entre codón y anticodón constituye uno de los principales mecanismos responsables de la fidelidad de la traducción genética. Cuando un ARNt cargado con su aminoácido correspondiente ingresa al ribosoma, la estabilidad del apareamiento entre el codón y el anticodón es evaluada por múltiples mecanismos de control molecular. Solamente las interacciones suficientemente precisas desencadenan los cambios conformacionales necesarios para permitir la incorporación del aminoácido a la cadena polipeptídica en crecimiento.
Sin embargo, la relación entre codones y anticodones no siempre es estrictamente uno a uno. El código genético presenta una propiedad denominada degeneración, según la cual varios codones diferentes pueden codificar un mismo aminoácido. Debido a ello, el número de moléculas distintas de ARNt presentes en una célula suele ser menor que el número total de codones que especifican aminoácidos. Esta aparente discrepancia se explica mediante la hipótesis del balanceo o “wobble”.
La hipótesis del balanceo establece que el apareamiento entre la tercera base del codón y la primera base del anticodón puede presentar cierta flexibilidad estructural. Como consecuencia, un mismo anticodón puede reconocer más de un codón relacionado. Este fenómeno es posible gracias a modificaciones químicas presentes en diversas bases del ARNt, particularmente la inosina, que posee la capacidad de establecer apareamientos con múltiples nucleótidos diferentes. Gracias al mecanismo de balanceo, un número relativamente reducido de ARNt puede reconocer eficientemente los 61 codones que especifican aminoácidos.
Las modificaciones químicas postranscripcionales representan otra característica fundamental de los ARNt. Después de su síntesis inicial, estas moléculas experimentan numerosas modificaciones en bases específicas. Actualmente se conocen más de 100 tipos diferentes de nucleósidos modificados presentes en ARNt de distintos organismos. Estas modificaciones contribuyen a la estabilidad estructural de la molécula, mejoran la precisión del reconocimiento codón-anticodón, favorecen la interacción con los ribosomas y participan en mecanismos reguladores que modulan la eficiencia de la traducción.
La interacción entre codón y anticodón ocurre dentro de regiones específicas del ribosoma conocidas como sitio A, sitio P y sitio E. Cuando un nuevo ARNt cargado entra al sitio A, su anticodón examina el codón expuesto del ARNm. Si el apareamiento es correcto, el aminoácido transportado es incorporado a la cadena polipeptídica mediante la formación de un enlace peptídico. Posteriormente, el ribosoma avanza a lo largo del ARNm y el proceso se repite sucesivamente hasta completar la proteína.
La fidelidad global de la síntesis proteica depende de múltiples niveles de control. El primero corresponde a la selección correcta del aminoácido por las aminoacil-ARNt sintetasas. El segundo involucra la correcta carga del ARNt. El tercero corresponde al reconocimiento específico entre codón y anticodón dentro del ribosoma. Finalmente, mecanismos adicionales de vigilancia molecular detectan y eliminan errores potenciales durante la elongación de la cadena polipeptídica. La acción coordinada de todos estos sistemas permite alcanzar niveles de precisión extraordinariamente elevados, indispensables para mantener la integridad funcional del proteoma celular.
Los anticodones constituyen uno de los elementos más conservados del aparato de traducción. Su conservación refleja la enorme presión selectiva ejercida sobre la fidelidad de la síntesis proteica. Incluso pequeñas alteraciones en la capacidad de reconocimiento entre codones y anticodones pueden generar errores de traducción que conduzcan a proteínas defectuosas, pérdida de función celular o alteraciones patológicas.
Los anticodones representan el mecanismo molecular mediante el cual la información genética codificada en el ARNm es interpretada con precisión. Gracias a la complementariedad específica entre codones y anticodones, cada aminoácido es incorporado en la posición exacta determinada por la secuencia genética. Este proceso constituye uno de los ejemplos más notables de reconocimiento molecular en los sistemas biológicos y representa un componente esencial para la expresión correcta de la información genética en todos los organismos vivos.


Fuente y lecturas recomendadas:
- Alberts, B., Johnson, A., Lewis, J., Morgan, D., Raff, M., Roberts, K., & Walter, P. (2022). Molecular biology of the cell (7th ed.). W. W. Norton & Company.
- Crick, F. H. C. (1966). Codon-anticodon pairing: The wobble hypothesis. Journal of Molecular Biology, 19(2), 548–555. https://doi.org/10.1016/S0022-2836(66)80022-0
- Giegé, R., Jühling, F., Pütz, J., Stadler, P., Sauter, C., & Florentz, C. (2012). Structure of transfer RNAs: Similarity and variability. Wiley Interdisciplinary Reviews: RNA, 3(1), 37–61. https://doi.org/10.1002/wrna.103
- Jackman, J. E., & Alfonzo, J. D. (2013). Transfer RNA modifications: Nature’s combinatorial chemistry playground. Wiley Interdisciplinary Reviews: RNA, 4(1), 35–48. https://doi.org/10.1002/wrna.1144
- Kim, S., & Waldor, M. K. (2019). Transfer RNA as an active regulator of biological processes. Nature Reviews Microbiology, 17(11), 705–718. https://doi.org/10.1038/s41579-019-0247-7
- Lodish, H., Berk, A., Kaiser, C. A., Krieger, M., Bretscher, A., Ploegh, H., Amon, A., & Martin, K. C. (2021). Molecular cell biology (9th ed.). W. H. Freeman.
- Rodnina, M. V. (2018). Translation in prokaryotes. Cold Spring Harbor Perspectives in Biology, 10(9), a032664. https://doi.org/10.1101/cshperspect.a032664
- Schimmel, P. (2018). The emerging complexity of the tRNA world: Mammalian tRNAs beyond protein synthesis. Nature Reviews Molecular Cell Biology, 19(1), 45–58. https://doi.org/10.1038/nrm.2017.77
- Steitz, T. A. (2008). A structural understanding of the dynamic ribosome machine. Nature Reviews Molecular Cell Biology, 9(3), 242–253. https://doi.org/10.1038/nrm2352
- Woese, C. R., Olsen, G. J., Ibba, M., & Söll, D. (2000). Aminoacyl-tRNA synthetases, the genetic code, and the evolutionary process. Microbiology and Molecular Biology Reviews, 64(1), 202–236. https://doi.org/10.1128/MMBR.64.1.202-236.2000
Aprende administración paso a paso

ADMINISTRACION DESDE CERO